This post is a write-up on a presentation I gave last year. You can check out the project on Github here or go here and press ‘s’ to get speaker notes.

I initially gave this presentation in November 2020 for the Asheville SQL Meetup. It covers the basics of SQL Server’s Machine Learning Services. Hopefully, it provides enough information to help people decide if this tech is a good solution for them.

This presentation covers some background on Machine Learning Services, like what it is and why you would want to use it. There’s a demo section that showcases three different ways to use R in production with SQL Server. Finally, there’s a section for some tips and tricks that helped me when I set up and use this tech.

The first section is just on the background.

Machine Learning Services is a SQL Server feature that allows you to bring analytics into the database by running the analytics programming language in-database. It first started in 2016 with R and later added Python support. Some old documentation will call it R services because that was the name before adding Python. This is not a standalone server. It’s a regular SQL Server with added features. There is another option for a standalone server. That might be a better choice for your needs, but we’ll not cover that in this presentation.

If you’re wondering if this would be a good addition to your tech stack, here are some excellent use cases: forecasting next month’s revenue, customer churn to predict when types of customers are mostly like to leave, and finding potential fraud in claims data. Basically, anything that is a best guess or probability. It’s not for pulling data or summaries. You can do that, but it won’t be better than using SQL typically. You can do some predictive modeling with just SQL, but usually, using R or Python has more features and is easier to use. Also, for this presentation, when I say ‘model’, I’m talking about a predictive or statistical model, not a data model that’s commonly used in SQL settings.

Speeding up predictive model processing is the main reason to add this tech. By bringing the analysis to the data, you don’t have to move large data sets out of SQL Server to get the results you need. This can cut out a huge amount of time and processing power. You get to utilize SQL for the data prep and R or Python for the analysis. This brings you the best of both worlds. SQL tends to be a lot more stable and optimized for data prep, while R and Python can handle the large machine learning models that would too difficult to code in SQL. Also, Machine Learning Services outputs within SQL Server, which is easily used for reporting or an ETL.

This setup also allows you to have clean analytics projects in production. There’s no need for large wonky code sets to get everything glued together. You can use all the standard SQL objects, like stored procedures and jobs. So, you don’t need another tool for scheduling or error reporting. There is less pipeline work since you’re not moving data in and out of SQL Server. So there are fewer ETLs, permissions issues, and other places for things to break.
I think the addition of ‘fewer things to break’ for this work is an important selling point. If you’re adding in tech, then you’re also adding in more options for failure. That’s made up for to get the predictive modeling capabilities but reducing all the other code helps put this option ahead of other predictive modeling tools. There are a variety of setups, but you can pick a specific one for your team or organization. The flexibility is nice, so this tool works for most companies. Then when you get a setup for your team, you can set standards, so everything follows a pattern for documentation and code.

This tech is a great setup because it can ease collaboration between data scientists and DBAs. It utilizes SQL permissions. So no one needs to learn a new setup for that, and it can fit nicely into your current structure. It has Microsoft-approved security. You’re not bringing in unvalidated software on your server. And it has options for resource controls. If you’re worried about data science work taking over everything, you can put up gates to prevent that. As a side note, I’ve never needed to use this feature. Most resource-intensive data science work happens during development, not running them in production, and I build the models in a different environment.

The real-time analysis can be too slow. We’ll compare different options during the demo section, so you’ll see the fast ones. If you can wait a few seconds to return results or run everything in a batch the night before you need them, you’re good to go. If machine learning services are too slow, then SQL Server is probably too slow.
The big data operations can be too small. This is more of a limitation of SQL Server again. Depending on your data size, this might not be big enough, but then SQL Server is probably not the right tool anyways.
This doesn’t work as well with Power BI and other interfaces as you might expect, especially for interactivity. If you can’t run a stored procedure or run all the options before pulling out the data, you’ll have a lot of limitations here.

When you’re planning out setting this up, there are a few things to figure out. You should have some idea of the roles you want involved. Machine learning services gives teams a whole spectrum of responsibilities that can be used to set expectations and tasks between DBAs and data scientist. So, you can have a setup with a ton of DBA involvement or very little work, depending on what you want at your company. You’ll want to know about the use cases you’ll have. In the demo section, we’ll walk through a few options. Determining which setup is best for your team is pretty much determined by your use cases. The number of people involved can also play a factor. You can easily interfere with other people’s work if you’re not careful, so some setups are better with larger teams. Overall, there is a lot of flexibility but no strong consensus on how to use this tech.

Now for the demo section.
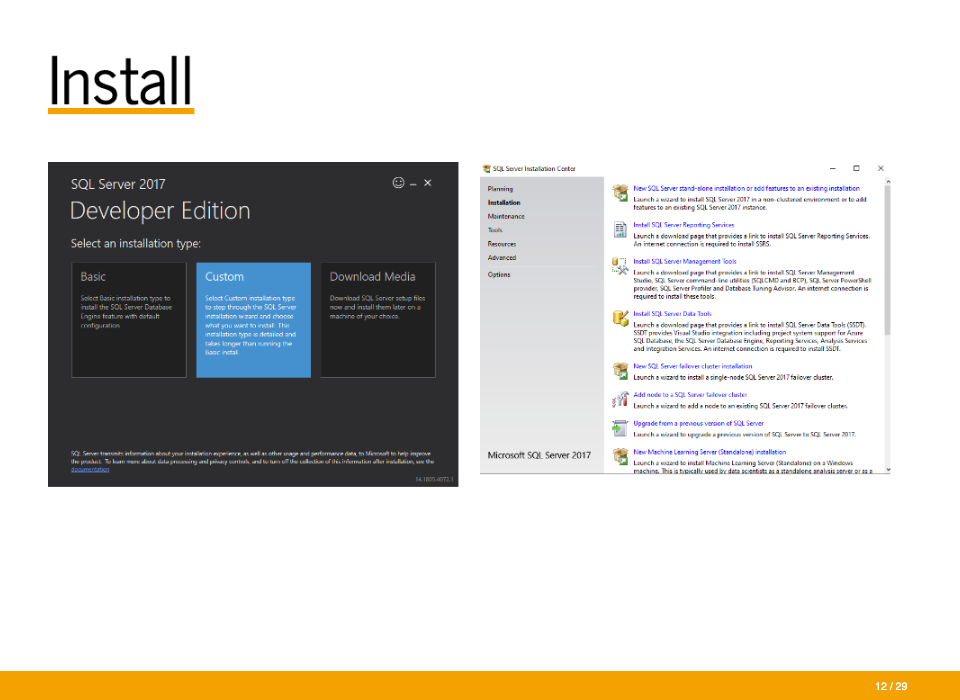
You need to have SQL Server installed first. I’m using the 2017 Developer Edition. You’ll go through normal installation for most of this. (https://www.microsoft.com/en-us/sql-server/sql-server-2017 - ‘Free download’ link near the bottom)
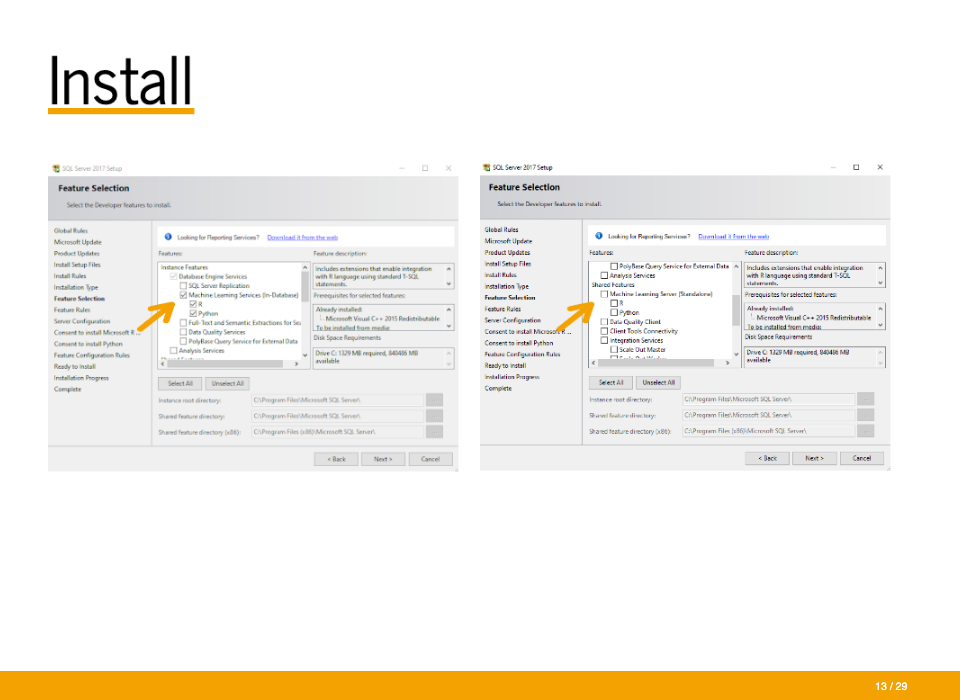
The main catch is making sure to check the boxes for Machine Learning Services (In-Database). You can pick R, Python, or both.
Do not pick Machine Learning Server (Standalone). That’s a different product.

You’ll go through a few more options and restarts. You can test that it’s working with a little ‘Hello World’ script.

The primary function you’ll use is sp_execute_external_script. It’s the way to access an external language. There are a bunch of parameters. The specific language (R or Python). The actual script to run. The input data set. The output data that gets returned. And a lot of other options too.

For a big disclaimer. I’ll run some code that creates predictive models, but I’m taking a lot of shortcuts. I’m not working through choosing a model, testing, and checking. I’m just getting a small model setup for the demo. The SQL objects and functions are fine to use. That’s the main focus of this presentation and can be adapted very easily for your company.

– run 1_set_up_checks.sql
/* EXEC sp_configure 'external scripts enabled', 1
RECONFIGURE WITH OVERRIDE */
-- EXECUTE sp_configure 'external scripts enabled'
EXEC sp_execute_external_script @language = N'R',
@script = N'
OutputDataSet <- InputDataSet;
',
@input_data_1 = N'SELECT 1 AS hello'
WITH RESULT SETS (([hello] int not null));
GO
-- Check Version
EXECUTE sp_execute_external_script @language = N'R'
, @script = N'print(version)';
GO
-- R Packages
EXEC sp_execute_external_script @language = N'R'
, @script = N'
OutputDataSet <- data.frame(installed.packages()[,c("Package", "Version", "Depends", "License", "LibPath")]);'
WITH result sets((
Package NVARCHAR(255)
, Version NVARCHAR(100)
, Depends NVARCHAR(4000)
, License NVARCHAR(1000)
, LibPath NVARCHAR(2000)
));This shows that everything looks good.
– run 2_create_mtcars.sql
-- mtcars database
CREATE TABLE dbo.mtcars(
mpg decimal(10, 1) NOT NULL,
cyl int NOT NULL,
disp decimal(10, 1) NOT NULL,
hp int NOT NULL,
drat decimal(10, 2) NOT NULL,
wt decimal(10, 3) NOT NULL,
qsec decimal(10, 2) NOT NULL,
vs int NOT NULL,
am int NOT NULL,
gear int NOT NULL,
carb int NOT NULL
);
INSERT INTO dbo.mtcars
EXEC sp_execute_external_script @language = N'R'
, @script = N'MTCars <- mtcars;'
, @input_data_1 = N''
, @output_data_1_name = N'MTCars';
SELECT * FROM dbo.mtcars;
--DROP TABLE dbo.mtcars;This builds out a test data set for us to use.
– run 3_mtcars_sql.sql
-- Input data set
SELECT mpg, cyl, hp, wt FROM dbo.mtcars;
-- 1974 Motor Trends
-- miles per gallon
-- number of cylinders
-- horse power
-- weight (1000 lbs)
-- Build the model -----------------------------------------------------------------------
EXEC sp_execute_external_script
@language = N'R'
, @script = N'cars_model <- lm(mpg ~ cyl + hp + wt, data = mtcars_data);
trained_model <- data.frame(model = as.raw(serialize(cars_model, connection=NULL)));'
, @input_data_1 = N'SELECT mpg, cyl, hp, wt FROM dbo.mtcars'
, @input_data_1_name = N'mtcars_data'
, @output_data_1_name = N'trained_model'
WITH RESULT SETS ((model VARBINARY(max)))
CREATE TABLE predictive_models (
model_name varchar(30) not null default('default model') primary key,
model varbinary(max) not null
);
INSERT INTO predictive_models(model)
EXEC sp_execute_external_script
@language = N'R'
, @script = N'cars_model <- lm(mpg ~ cyl + hp + wt, data = mtcars_data);
trained_model <- data.frame(model = as.raw(serialize(cars_model, connection=NULL)));'
, @input_data_1 = N'SELECT mpg, cyl, hp, wt FROM MTCars'
, @input_data_1_name = N'mtcars_data'
, @output_data_1_name = N'trained_model';
SELECT * FROM [master].[dbo].[predictive_models];
UPDATE predictive_models
SET model_name = 'lm_' + format(getdate(), 'dd-MM-yy')
WHERE model_name = 'default model'
SELECT * FROM [master].[dbo].[predictive_models];
--DROP TABLE dbo.predictive_models;
-- Run model ---------------------------------------------------------------------------
DECLARE @selected_lmmodel varbinary(max) =
(SELECT model FROM dbo.predictive_models WHERE model_name = 'lm_17-11-20');
EXEC sp_execute_external_script
@language = N'R'
, @script = N'
current_model <- unserialize(as.raw(lmmodel));
new <- data.frame(mtcars_data);
predicted.am <- predict(current_model, new);
str(predicted.am);
OutputDataSet <- cbind(new, predicted.am);
'
, @input_data_1 = N'SELECT cyl, hp, wt FROM dbo.mtcars'
, @input_data_1_name = N'mtcars_data'
, @params = N'@lmmodel varbinary(max)'
, @lmmodel = @selected_lmmodel
WITH RESULT SETS ((cyl INT, hp INT, wt DECIMAL(10, 2), predicted_mpg DECIMAL(10, 2)));This builds a model, saves it to a new table, and scores data with the new model. You can add more models to this table or update the existing ones. This is the most basic setup. Everything’s pretty much kept in SQL Server with basic functionalities.

There is an option for Native Scoring. This doesn’t use the overhead of R and Python but uses another format. The trade-off is there is a smaller list of possible models, but these are the most common. You’ll use RevoScaleR or revoscalepy, depending on if you’re using R or Python. The main function here is PREDICT. So look for that in the code. (Open Neural Network Exchange (ONNX))

– run 4_mtcars_nativescoring.sql
-- Input data set
SELECT mpg, cyl, hp, wt FROM dbo.mtcars;
-- Build the model -----------------------------------------------------------------------
DECLARE @model varbinary(max);
EXECUTE sp_execute_external_script
@language = N'R'
, @script = N'
cars_model <- rxLinMod(mpg ~ cyl + hp + wt, data = mtcars_data)
model <- rxSerializeModel(cars_model, realtimeScoringOnly = TRUE)'
, @input_data_1 = N'SELECT mpg, cyl, hp, wt FROM dbo.mtcars'
, @input_data_1_name = N'mtcars_data'
, @params = N'@model varbinary(max) OUTPUT'
, @model = @model OUTPUT
INSERT [dbo].[predictive_models]([model_name], [model])
VALUES('native_scoring', @model) ;
SELECT * FROM [master].[dbo].[predictive_models];
--DROP TABLE dbo.predictive_models;
-- Run model ---------------------------------------------------------------------------
DECLARE @model varbinary(max) = (
SELECT model
FROM [master].[dbo].[predictive_models]
WHERE model_name = 'native_scoring');
SELECT d.*, p.*
FROM PREDICT(MODEL = @model, DATA = dbo.mtcars as d)
WITH(mpg_Pred float) as p;
--DROP TABLE dbo.predictive_models;This builds the model, adds it to the table, and scores some data. You can see it is very similar to the other setup.

The last way to run a model in production I’ll talk about is using an R package. R packages are a pretty common mechanism to wrap up a lot of R code. You’ll see them for almost everything. This provides the most separation between R and SQL by wrapping up most of the R code in the package then using SQL to pass data to it. You can make changes to the package to change the model instead of changing any SQL code. You’ll just need to use an ALTER statement to update it. This is probably the cleanest route for when a lot of R code needs to run.

When you’re creating a model to use in a package, there might be some versioning issues. Using these settings might resolve them.

– run 5_mtcars_rpackage.sql
CREATE EXTERNAL LIBRARY mtcarsmodel
FROM (CONTENT = 'mtcarsmodel_0.1.0.zip') WITH (LANGUAGE = 'R'); --pull from GitHub
EXEC sp_execute_external_script @language = N'R'
, @script = N'
OutputDataSet <- data.frame(installed.packages()[,c("Package", "Version", "Depends", "License", "LibPath")]);'
WITH result sets((
Package NVARCHAR(255)
, Version NVARCHAR(100)
, Depends NVARCHAR(4000)
, License NVARCHAR(1000)
, LibPath NVARCHAR(2000)
));
-- !!! NOTE THE DIFFERENT LIBPATH !!! ---
-- DROP EXTERNAL LIBRARY mtcarsmodel;
EXEC sp_execute_external_script
@language =N'R',
@script=N'library(mtcarsmodel)';
-- Note the warning message about R 4.0.0
-- Run model ---------------------------------------------------------------------------
EXEC sp_execute_external_script
@language = N'R'
, @script = N'
library(mtcarsmodel)
OutputDataSet <- mtcarsmodel::predict_mtcars(mtcars_data);'
, @input_data_1 = N'SELECT cyl, hp, wt FROM dbo.mtcars'
, @input_data_1_name = N'mtcars_data'
WITH RESULT SETS ((cyl INT, hp INT, wt DECIMAL(10, 2), predicted_mpg DECIMAL(10, 2)));–(Make sure to have the package pulled from GitHub and saved in as a zipfile.)
This code uploads an R package that contains a pre-built model. It then uses machine learning services to score data with that package.

– run 6_mt_cars_big.sql
-- mtcars big table
CREATE TABLE dbo.mtcars_big(
mpg decimal(10, 1) NOT NULL,
cyl int NOT NULL,
disp decimal(10, 1) NOT NULL,
hp int NOT NULL,
drat decimal(10, 2) NOT NULL,
wt decimal(10, 3) NOT NULL,
qsec decimal(10, 2) NOT NULL,
vs int NOT NULL,
am int NOT NULL,
gear int NOT NULL,
carb int NOT NULL
);
INSERT INTO dbo.mtcars_big
EXEC sp_execute_external_script @language = N'R'
, @script = N'MTCars <- mtcars[sample(1:nrow(mtcars), 1000000, replace = TRUE), ];'
, @input_data_1 = N''
, @output_data_1_name = N'MTCars';
--DROP TABLE dbo.mtcars_big;
CREATE TABLE #mtcars_big_predictions (
cyl INT,
hp INT,
wt DECIMAL(10, 2),
mpg_Pred FLOAT)
/* SQL */ -------------------------------------------------------------------------------------------
DECLARE @lmmodel varbinary(max) =
(SELECT model FROM dbo.predictive_models WHERE model_name = 'lm_17-11-20'); -- MAKE SURE TO CHANGE THE MODEL NAME
INSERT INTO #mtcars_big_predictions
EXEC sp_execute_external_script
@language = N'R'
, @script = N'
current_model <- unserialize(as.raw(lmmodel));
new <- data.frame(mtcars_data);
predicted.am <- predict(current_model, new, type = "response");
str(predicted.am);
OutputDataSet <- cbind(new, predicted.am);
'
, @input_data_1 = N'SELECT cyl, hp, wt FROM dbo.mtcars_big'
, @input_data_1_name = N'mtcars_data'
, @params = N'@lmmodel varbinary(max)'
, @lmmodel = @lmmodel;
-- Seconds: 16
-- check results
SELECT TOP 1000 * FROM #mtcars_big_predictions;
TRUNCATE TABLE #mtcars_big_predictions;
/* Native Scoring */ -------------------------------------------------------------------------------------------
DECLARE @model varbinary(max) = (
SELECT model
FROM [master].[dbo].[predictive_models]
WHERE model_name = 'native_scoring');
INSERT INTO #mtcars_big_predictions
SELECT d.cyl, d.hp, d.wt, p.*
FROM PREDICT(MODEL = @model, DATA = dbo.mtcars_big as d)
WITH(mpg_Pred float) as p;
-- Seconds: 8
-- check results
SELECT TOP 1000 * FROM #mtcars_big_predictions;
TRUNCATE TABLE #mtcars_big_predictions;
/* R Package */ ---------------------------------------------------------------------------------------------
INSERT INTO #mtcars_big_predictions
EXEC sp_execute_external_script
@language = N'R'
, @script = N'
library(mtcarsmodel)
OutputDataSet <- mtcarsmodel::predict_mtcars(mtcars_data);'
, @input_data_1 = N'SELECT cyl, hp, wt FROM dbo.mtcars_big'
, @input_data_1_name = N'mtcars_data';
--WITH RESULT SETS ((cyl INT, hp INT, wt DECIMAL(10, 2), predicted_mpg DECIMAL(10, 2)));
-- Seconds: 14
-- check results
SELECT TOP 1000 * FROM #mtcars_big_predictions;
TRUNCATE TABLE #mtcars_big_predictions;
-- DROP TABLE dbo.mtcars_big;
-- Try this with clearing cacheThis code builds out a bigger data set to see run time comparisons. It’s good for a lot of batch analytics, and the native scoring is the best.

Now for the tips and tricks section.

Small catches and errors will definitely be the most painful part. You’ll hit a lot of minor mistakes the first time you try to get something working. Here are a few to watch out for in your work. R and Python are case-sensitive. So the input data names have to match exactly, unlike SQL. Input/output formats can trouble. This includes the number of columns, names, and data types. R, Python, and SQL Server have slightly different data types. So, you might hit a weird issue, especially with conversions. Error messaging can be cloudy at best. You’ll get a lot of weird messages that are either a downstream effect of the real problem or are just some esoteric response. You can get this if there’s something wrong in the R code, but you’ll get the final issue as a SQL problem.
There is also a whole world of versioning that we won’t get to in this presentation. You’ll need to look into upgrading versions of Machine Learning Services. Probably choose something using miniCran, R Open, and the checkpoint package. Finally, you’ll need to figure out any dependencies for the packages of predictive models you might have. The tech on the last bullet point can help you out here.

A lot of documentation and blog posts are hit or miss because they deal with outdated practices or features that don’t work with your setup. If you search around enough, you will find some help eventually though.
You can use all the standard SQL objects/tools. Everything can be wrapped up in a stored procedure, which can be very nice. You can save and update models in a temporal table to compare model performance over time. And you can use a separate for all models or a different database for each project to keep data pulls, reference tables, and outputs altogether.

Make sure to write documentation as you go. Then at the end, delete the setup and restart following the documentation. You’ll probably want to delete and restart several times. There will be little catches you’ll need to remember later, and having them written down will save you.
I like to script everything. I find it easier for reproducibility and to pass off stuff to coworkers. If you mainly have an R shop, the sqlmlutils package will be helpful. If you’re mainly SQL, you can use standard SQL code for everything. At my job, everything gets passed off to another developer for putting models on our production server. I’ve got scripts that pick up the R packages, place them in the right spot, and test everything.
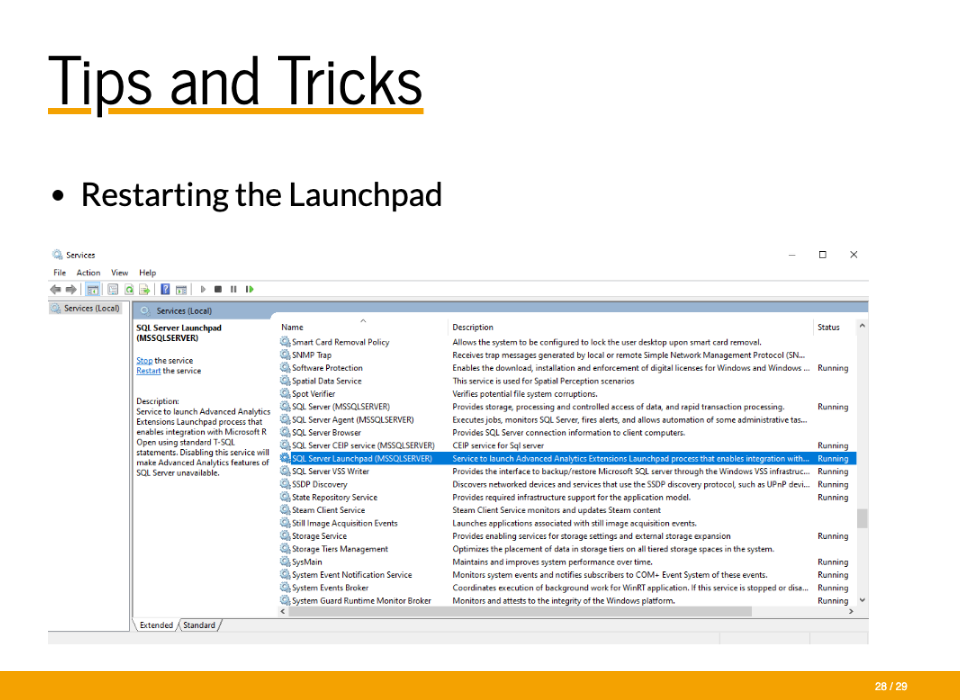
Lastly, sometimes in development Machine Learning Services will stop working. The main place to check is restarting the launchpad. This will fix it most of the time. There’s nothing really special about this slide. Just to know to do this because you’ll almost definitely run into this issue.
